Resources
I wanted to see if I could create a Twitter bot and a complementary moderation layer similar to social-media-management tools like Tweetdeck; I’d found myself getting into small rituals finding entertaining online-content, and wanted to automate and share the outcome instead of spamming my friends with links. My favourite candidate idea was a combination of games analytics and dramatic irony: ridiculous Steam reviews.
Having played around with Steam’s review API in the past, I did some sketching for a potential system
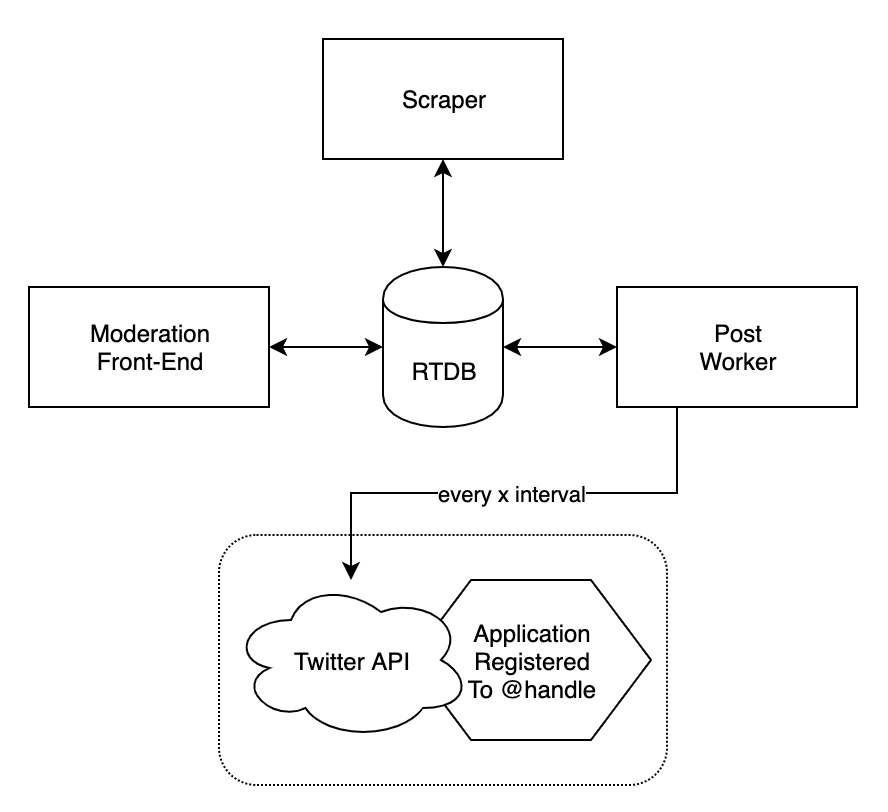
The architectural diagram for the project, with Heroku as the worker host and Firebase as the front-end host
I knew I’d have to:
- Retrieve interesting data programatically and periodically
- Siphon the data using some criteria
- Store the filtered data somewhere
- Moderate which bits should be posted onto a queue
- Post from the queue with
Scraping
I started with a scraper that spitballed some criteria and used SteamSpy‘s API to get game listings (see Gist).
Initially, the criteria was to find games with an active playerbase, and negative reviews left by people who’d spent more than ten times the amount of hours as the average reviewer. I wanted to see personas evolve around these reviewers - why do they spend so much time playing something they so detest?
async function getGame(appId) {
return fetch(`https://steamspy.com/api.php?request=appdetails&appid=${appId}`)
.then(res => res.json())
.then((data) => {
return {
"id": appId,
"name": data.name,
"developer": data.developer,
"averagePlaytimeForever": data.average_forever,
"negative": data.negative
};
});
}With a mechanism to retrieve game data, I iterated over all reviews for that game – the console output was enough to slow the request time to below Steam’s 4-per-second rate-limit.
async function scrapeASinglePageOfReviews(game, cursor) {
if (cursor) {
cursor = encodeURIComponent(cursor);
}
let reviewUrl = `https://store.steampowered.com/appreviews/${game.id}?json=1&filter=recent&language=english&review_type=negative&purchase_type=all&num_per_page=100&cursor=${cursor ? cursor : ""}`;
return fetch(reviewUrl).then(res => { try {
return res.json() }
catch(e) {
return null;
}}).then((data) => {
if (data === null) {
console.log(`WARNING: END OF JSON INPUT FOR GAME ${game.id}`);
return null;
}
if (data.success && data.query_summary.num_reviews > 0) {
for (const review of data.reviews) {
if (reviewMeetsCriteria(game, review) && !hasBeenManuallyProcessed(review)) {
const reviewTruncated = {
"id": review.recommendationid,
"gameId": game.id,
"gameName": game.name,
"hoursPlayed": Math.floor(review.author.playtime_forever / 60),
"text": review.review.replace(/^\s+|\s+$/g, '').replace(/\s+/g, ' ').replace(/\r?\n|\r/g, ''),
"freebie": review.received_for_free,
"early": review.written_during_early_access
};
database.ref(`candidates/${reviewTruncated.gameId}/${reviewTruncated.id}`).set(reviewTruncated);
}
}
return data.cursor;
} else {
return null;
}
});
}I decided to use Firebase since it is free and quick to set up. Lastly, I could nest these calls in some loops to get data from the most popular games of the last two weeks – games meeting my criteria would be processed, and reviews of those games meeting my criteria would be pushed into the data store.
Moderating
I converted the above Node project into a Vue.js project – in this way, calls could be made via a CORS-proxy in the browser, simplifying the process of scraping to the point that it could be done on my mobile phone in my down-time as opposed to in a terminal. This was my first time using Vue, and I found it to be quite intuitive – component driven frameworks marry well with simple interfaces.
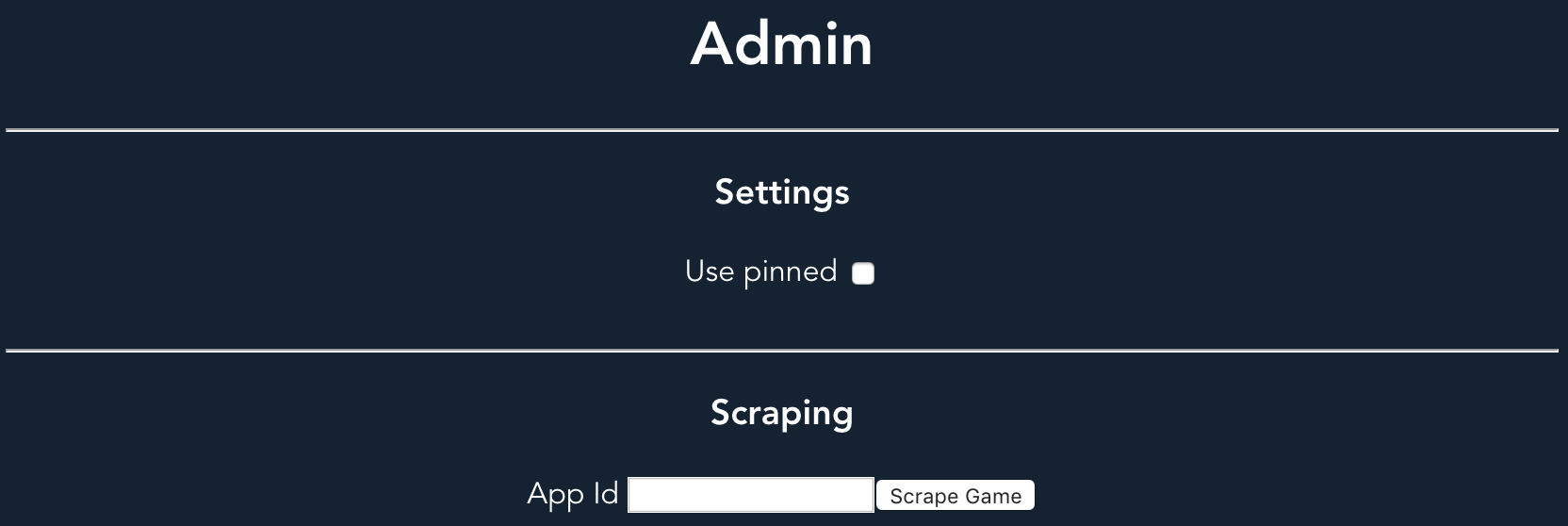

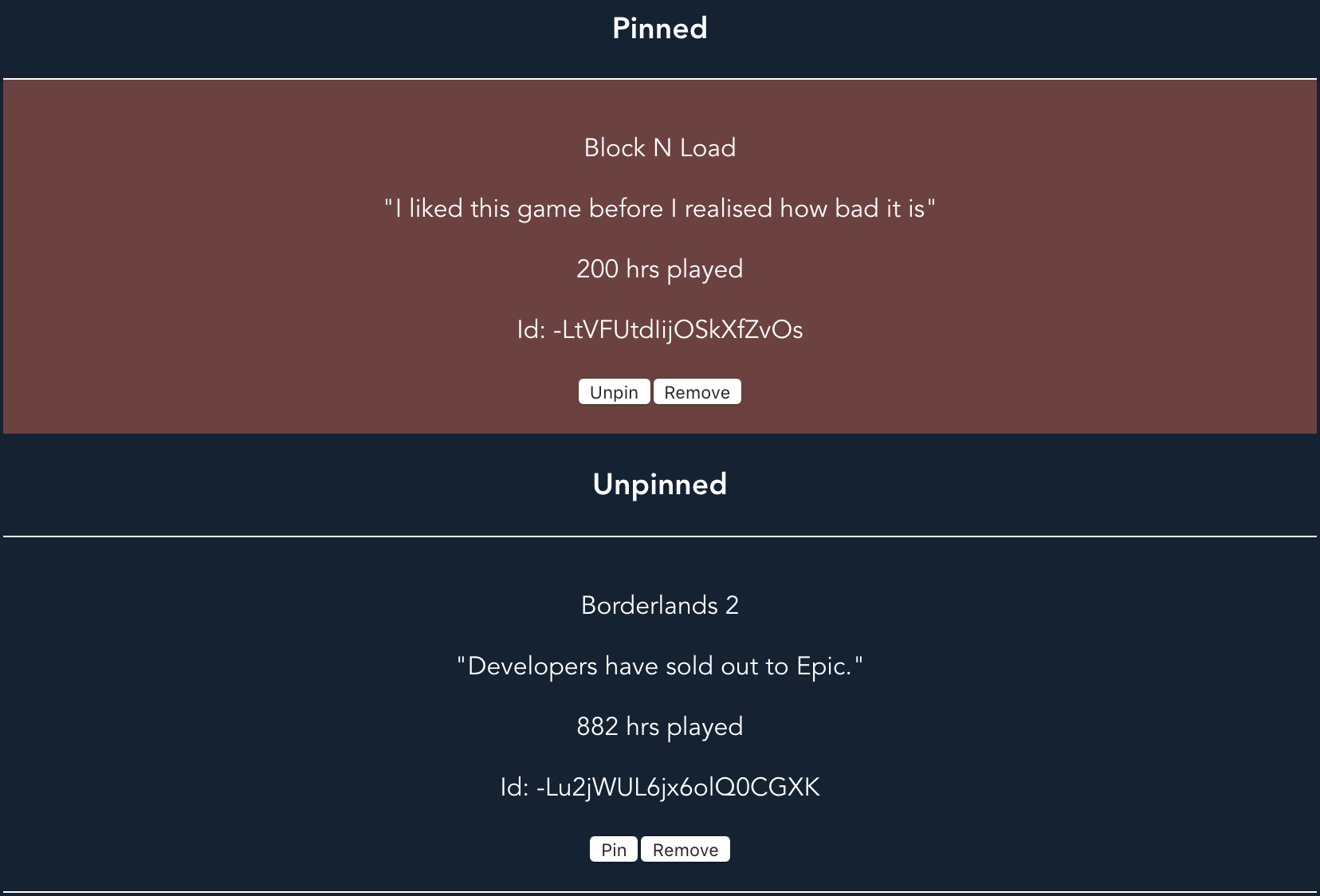
A game can be scraped by its ID, and global post settings controlled.
Posting
Now for the fun bit! I wrote a worker (see Gist) to run on Heroku – again, free and easy. It takes a random review off the queue (weighted against recently posted games), formats the post, includes an image from Steam, logs it and then posts it to the @superfanreviews Twitter account.
/**
* Processing loop - let there be tweets!
*/
async function step() {
const previousReviewGameIds = await getPreviousReviewGameIds(NUM_PREVIOUS_REVIEWS);
const review = await getRandomReviewFromQueue(previousReviewGameIds);
if (!review) {
console.log('Could not find review.');
return;
}
const game = await getGame(review);
let outcome = -1;
do {
outcome = await postReview(review, game);
console.log(outcome);
} while (outcome === -1);
}
setInterval(step, POST_CADENCE);Updating
I registered the bot with Botwiki, who are a fantastic catalogue-community of open-source bot developers. Thanks to a small nudge from their Twitter account, I was able to start picking up followers, and could therefore ask them what they’d like to see – I ran a poll to determine a post cadence of 4.5 hours.
After seeing some unsavoury things make it into my system, I added a profanity filter from NPM.
After seeing reviews get posted for the same game multiple times in a row (thanks Math.random()…), I made sure the worker would re-roll a few times if the review it picked matched any of the recent games in order to ensure diverse content.
When Halloween came around, I used the “pinned” feature in my worker to prioritise reviews that had been moderated as “pinned” first, essentially creating a sandboxed queue I could fill exclusively with horror games.
I’ve since been adding features to the moderation client, and tuning the criteria to ensure that moderating these funny, perplexing game reviews continues to be fun for me.
In regards to the reviews themselves, while myself and others find them funny, I also think they are valuable – running them through word-clouds for each game, they expose trends. For living-games, most appear to complain about monetisation, or abandonment. For single-player games, most complain about bugs. The data may be helpful in exposing addictive behaviours in digital-media, and providing developers with intensified feedback from those with a deep investment in their products.

There's more potential in the data set
Issues
Since this project was somewhat slapdash, there are aspects I’d like to improve:
- There is no caching of data, and ergo the read/write quota on my Firebase RTDB is dependent on how frequently I use the moderation tool.
- There is no authorisation on the moderation tool and ergo the links cannot be shared.
- The content is limited by Twitter’s character limit – perhaps I can create images in the future?
- Although I am requesting English reviews, some marked as English contain different languages (and BB-codes!)
