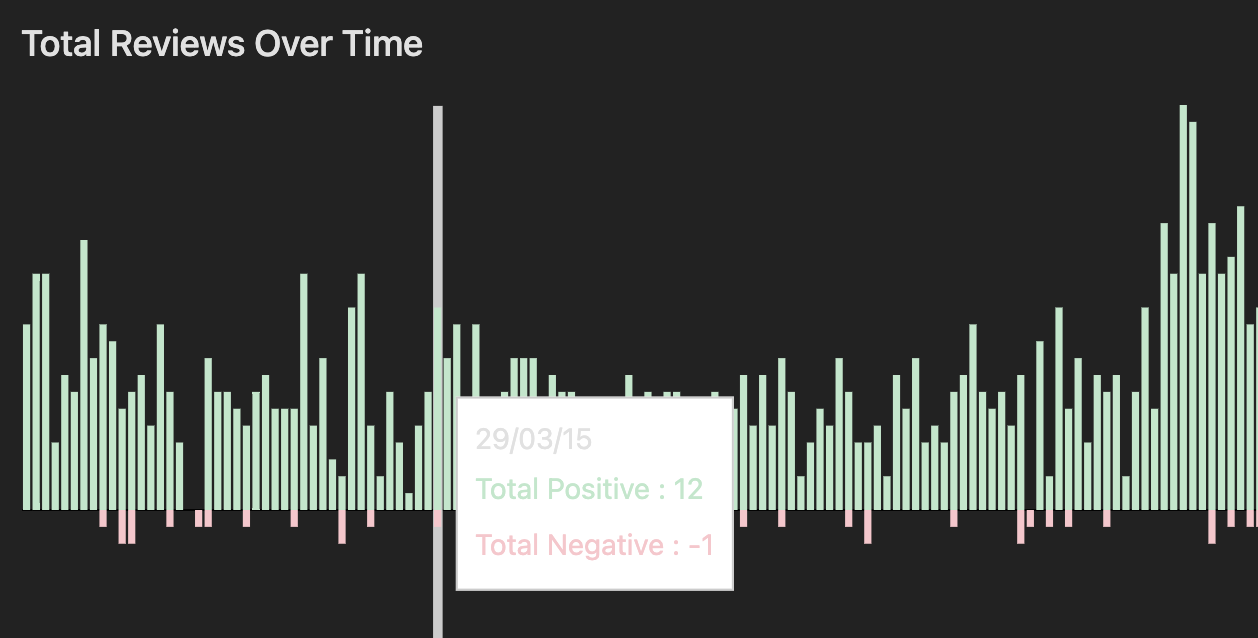
There are now a huge number of user reviews in Steam, but the only place to view them is the store front, which is geared towards consumers. However, Steam's APIs can be used to access all reviews for a given product at once, and more. This tool provides a clean interface to this data set with a greater level of control.
It is intended to answer a number of interesting and useful questions such as:
- How long do people typically play this game?
- What do people like/dislike most about it?
- What is the current trend in user sentiment after the last update compared to previous updates?
- Which users are having technical issues?
- Do people who receive it for free rate it more favourably?
A community manager may use it to find dedicated users worth helping and rewarding. A designer may use it to isolate high quality feedback. A product analyst may use it evaluate success (retention, sentiment) over time.
To this end, visualisations are provided to aid exploration, and the data itself can be exported.
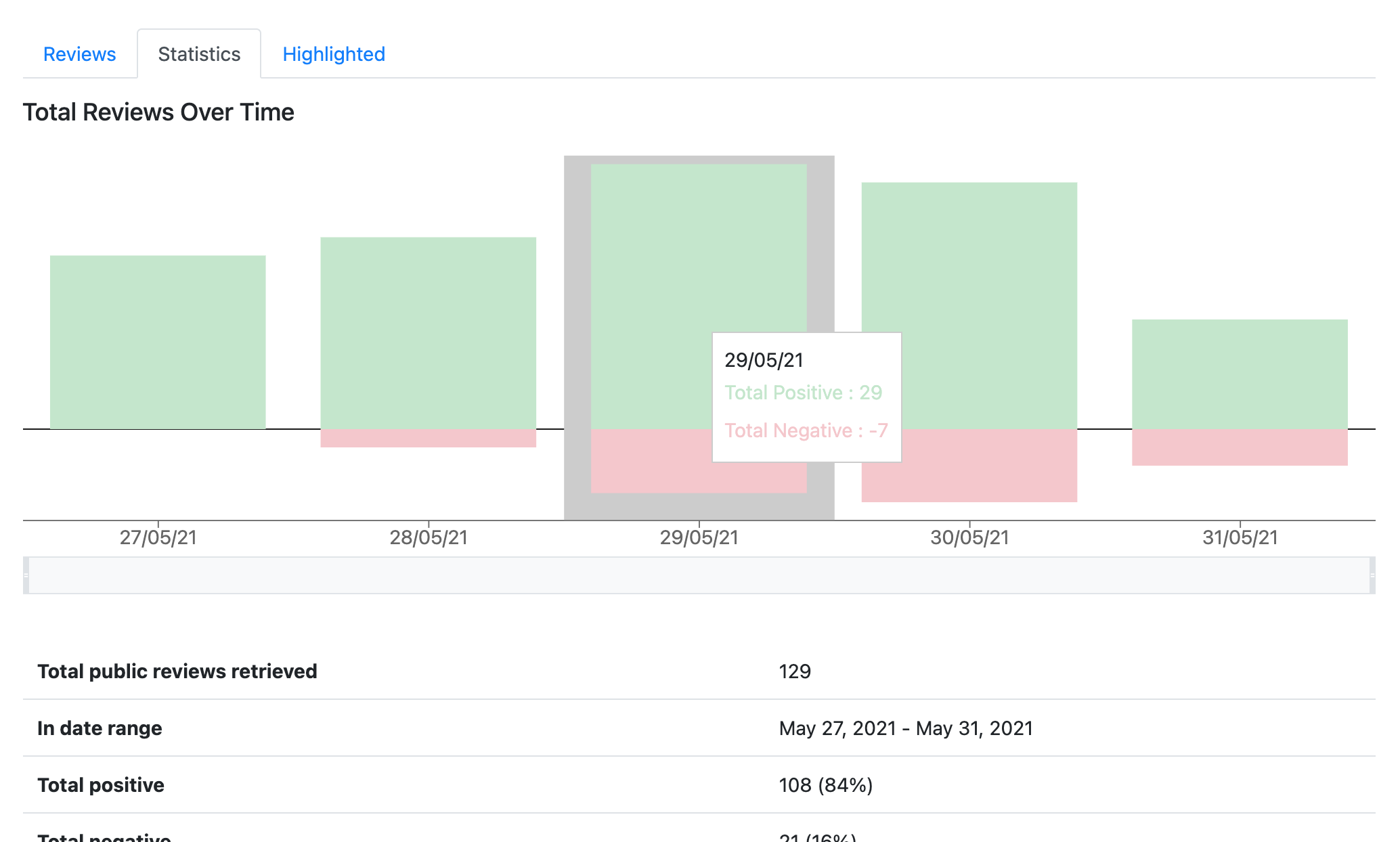
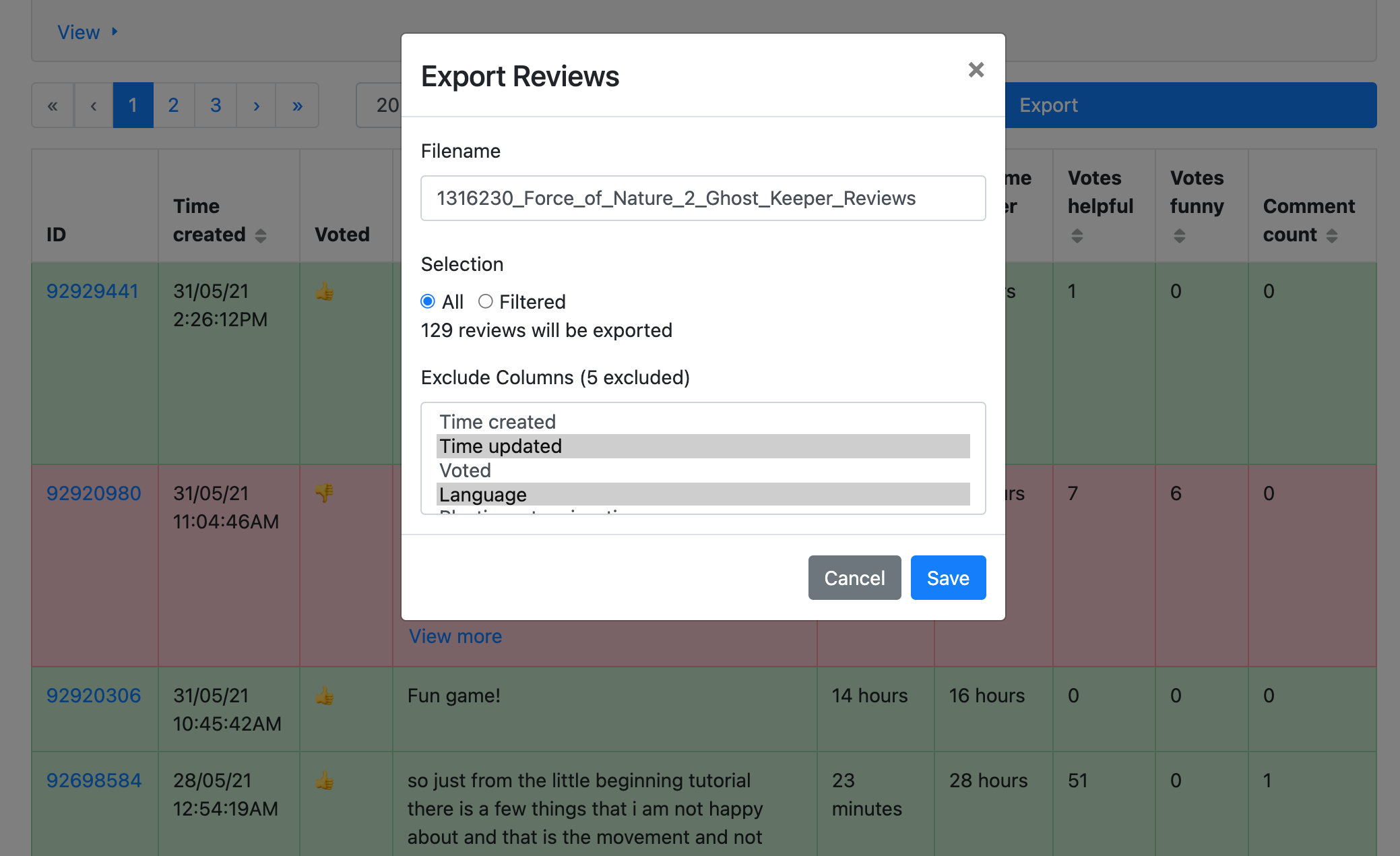
Technology
The web requests are funnelled through a CORS proxy that I host on Heroku, and the data itself is stored in your browser's memory. This isn't terribly efficient, but it cuts costs and ensures that indies with < 50,000 reviews can access the most up-to-date information about their games. If it were to ever suffer from success in terms of performance or rate-limiting, I'd have to write some back-end services with extra caching and their own data stores.
Reception
I created a feedback form for the site and posted the link on Reddit, where it briefly hit the front-page. I've been overwhelmed with positive responses and useful suggestions as I continue to support the tool, and have implemented quality-of-life features such as a dark mode, more graceful error handling and further filtering options. My favourite so far has been a filter that uses some RegEx magic to find reviews that contain ASCII art.
I hope that it sits alongside its influences of SteamDB and SteamSpy as an alternative method of exploring data. Steam's API itself seems to be in a state of flux, and I will likely have to continue to program around certain obstacles like incorrectly labelled or missing data, and aberrant failing requests.
